Abstract
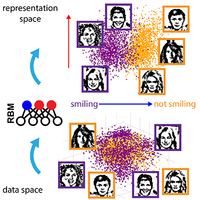
A goal of unsupervised machine learning is to build representations of complex high-dimensional data, with simple relations to their properties. Such disentangled representations make it easier to interpret the significant latent factors of variation in the data, as well as to generate new data with desirable features. The methods for disentangling representations often rely on an adversarial scheme, in which representations are tuned to avoid discriminators from being able to reconstruct information about the data properties (labels). Unfortunately, adversarial training is generally difficult to implement in practice. Here we propose a simple, effective way of disentangling representations without any need to train adversarial discriminators and apply our approach to Restricted Boltzmann Machines, one of the simplest representation-based generative models. Our approach relies on the introduction of adequate constraints on the weights during training, which allows us to concentrate information about labels on a small subset of latent variables. The effectiveness of the approach is illustrated with four examples: the CelebA dataset of facial images, the two-dimensional Ising model, the MNIST dataset of handwritten digits, and the taxonomy of protein families. In addition, we show how our framework allows for analytically computing the cost, in terms of the log-likelihood of the data, associated with the disentanglement of their representations.
- Received 21 July 2022
- Revised 16 January 2023
- Accepted 8 March 2023
DOI:https://doi.org/10.1103/PhysRevX.13.021003
Published by the American Physical Society under the terms of the Creative Commons Attribution 4.0 International license. Further distribution of this work must maintain attribution to the author(s) and the published article’s title, journal citation, and DOI.
Published by the American Physical Society
Physics Subject Headings (PhySH)
Popular Summary
Finding meaningful representations of complex data in automatic ways is a long-standing goal of machine learning. Representations should capture enough information about the data to guarantee high-fidelity reconstruction, discard irrelevant details, and have simple relations with important features underlying the data distribution. Methods for disentangling representations often rely on an adversarial game, where two neural networks compete while mutually improving their performances. However, this approach generally suffers from numerical instabilities and is difficult to implement in practice. We show how disentanglement can be achieved with a single model, in which parameters are adequately constrained.
We illustrate our approach on restricted Boltzmann machines (RBMs), a simple kind of network with one layer for data configurations and another for representations. RBMs are widely applicable in many contexts, where limitations on the quantity of available data preclude the usage of more complex, deeper architectures. The simplicity of RBMs makes them amenable to analytical calculations, which elucidates the role of the constraints.
Our approach allows us to better understand the cost (in terms of quality of the generated data) associated with disentanglement. We hope it will also make controlled generation of data and feature discovery easier in future applications. Besides the applications to RBMs we present here, our constraint-based framework could in principle be applied to other unsupervised architectures.