Abstract
We argue that an excess in entanglement between the visible and hidden units in a quantum neural network can hinder learning. In particular, we show that quantum neural networks that satisfy a volume law in the entanglement entropy will give rise to models that are not suitable for learning with high probability. Using arguments from quantum thermodynamics, we then show that this volume law is typical and that there exists a barren plateau in the optimization landscape due to entanglement. More precisely, we show that for any bounded objective function on the visible layers, the Lipshitz constants of the expectation value of that objective function will scale inversely with the dimension of the hidden subsystem with high probability. We show how this can cause both gradient-descent and gradient-free methods to fail. We note that similar problems can happen with quantum Boltzmann machines, although stronger assumptions on the coupling between the hidden and/or visible subspaces are necessary. We highlight how pretraining such generative models may provide a way to navigate these barren plateaus.
- Received 15 February 2021
- Revised 21 July 2021
- Accepted 13 October 2021
DOI:https://doi.org/10.1103/PRXQuantum.2.040316
Published by the American Physical Society under the terms of the Creative Commons Attribution 4.0 International license. Further distribution of this work must maintain attribution to the author(s) and the published article's title, journal citation, and DOI.
Published by the American Physical Society
Physics Subject Headings (PhySH)
Popular Summary
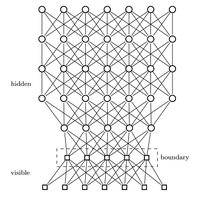
The promise of quantum machine learning is that by incorporating quantum effects, such as entanglement, into machine-learning models, researchers can improve model performance and understand more complex data sets. This hope is particularly pronounced in the design of deep quantum neural networks, which attempt to boost the performance of existing deep-learning models by allowing entanglement between the visible and hidden variables in the model. In our work, we show that applying this approach to quantum deep learning is problematic, given that an excess of entanglement between the hidden and visible layers can destroy the predictive power of these models. Our key insight is that barren plateaus, i.e., vanishing gradients as the model scales in the number of qubits, can occur as a result of an excess of entanglement between visible and hidden units in deep quantum neural networks.
This surplus of entanglement to some extent defeats the purpose of deep learning by causing information to be nonlocally stored in the correlations between the layers rather than in the layers themselves. As a result, when one tries to remove the hidden units, as is customary in deep learning, one finds that the resulting state is close to the maximally mixed state. Indeed, we show that such situations are generic and that gradient-descent methods are unlikely to allow the user to escape from such a plateau at a low cost. This suggests that if quantum effects are to be used, then they must be used surgically.